第 08 关 · 终极纪律
样本外与 walk-forwardOut-of-Sample & Walk-Forward
灵魂拷问:上一关那 11.5%,是真本事,还是又一个过拟合?这一关用“样本外”给你一个诚实的答案,然后你就毕业了。
1样本内决定,样本外验证
把数据切两段:前段(2018–2021)“定规则”,后段(2022–2026)“验证”。规则只能用前段看,后段是它从没见过的“考试卷”。
SPLIT = "202200"
in_sample = months < SPLIT # 决定规则只能用这段
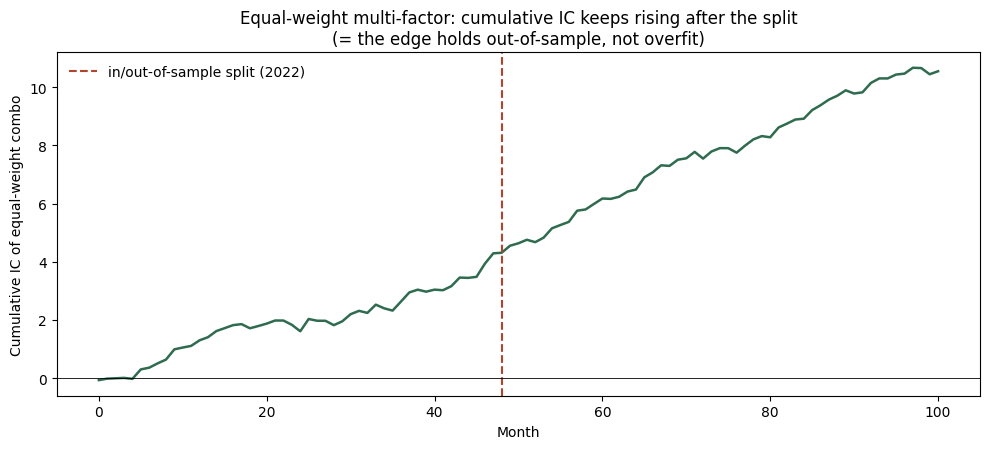
out_sample = months >= SPLIT # 这段只用来验证, 绝不回头调2等权综合因子:扛住了
| 做法 | 样本内超额 | 样本外超额 |
|---|---|---|
| 等权综合因子 | +5.3% | +6.9% |
| 样本内挑最强单因子 | (最强) | -1.7% |
| 按IC“优化”权重 | — | +3.5% |
等权综合因子样本外更强(+6.9%) → 上一关那个结果不是过拟合,是真本事(只是会缩水,正常)。
3反面教材:越优化越糟
样本内最强的那个单因子,样本外反而最差(−1.7%)——典型的“追涨杀跌式过拟合”。连“精心按 IC 加权”都只有 +3.5%,还不如无脑等权。简单往往赢过复杂。
4walk-forward 是什么
永远只用“过去”做决定,“未来”只拿来验证,然后滚动前进。等权综合因子不需要拟合任何参数(z-score 是每月横截面算的),所以天然就是 walk-forward 安全的——这也是它稳的原因。你一旦开始“优化权重/挑因子/调参”,就必须严格 walk-forward,否则就是第 04 关的过拟合。
🎓 毕业了
你掌握了量化研究的完整基本功。
价格→收益率 · 夏普与回撤 · 写策略与识破未来函数 · 过拟合/数据窥探/幸存者偏差 · 横截面与因子 · IC评价 · 多因子合成 · 样本外验证。
三句心法,带走:
① 量化不是找“涨最多”,是找“风险调整后稳定的小优势,大样本下放大”。
② 90% 的漂亮回测是 bug 或过拟合——会怀疑、会验证,比会写策略更值钱。
③ 简单 + 稳过样本外 > 复杂 + 样本内惊艳。
走完这 8 关,你已经能看懂本站四篇研究的核心套路了——它们就是把这套方法用在 LLM 读文本、龙虎榜席位等更前沿的题材上。