第 04 关 · 防自欺
回测的三大陷阱Three Ways Backtests Lie
这一关不教你赚钱,教你不被自己的回测骗。会拆穿漂亮回测,比会写漂亮回测值钱十倍。
1陷阱A · 过拟合(在历史上挑“最优参数”)
把一堆双均线参数都试一遍、挑样本内表现最好的那组:样本内夏普 1.36,看着真不错。但同一参数拿到样本外只剩 0.24;而且所有参数的样本外夏普均值才 0.05——“最优”并不比平均强。
本质:你不是发现了规律,是在历史噪声里挑了个最贴合的。换段时间就垮。怎么防:参数别在全样本上挑;少调参;一定看样本外(第 08 关专讲)。
2陷阱B · 数据窥探 / 多重检验
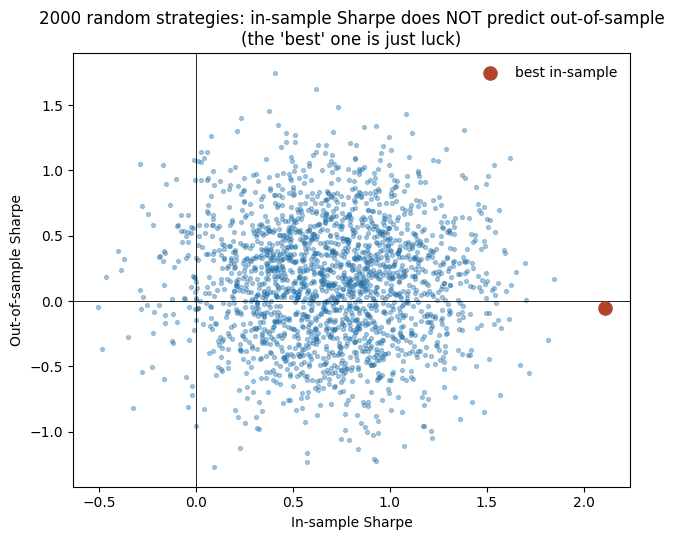
造 2000 个纯随机策略(每天瞎猜持有/空仓),其中“样本内最高夏普 2.11”——足以骗过很多人。但它样本外夏普 −0.05,而且全体样本内/外夏普相关性 ≈ 0(见图,点云毫无规律)。
best = -9
for _ in range(2000):
pos = np.random.randint(0, 2, n) # 每天随机持有/空仓
s_in = sharpe((pos*ret)[:split]) # 样本内
s_out = sharpe((pos*ret)[split:]) # 样本外
best = max(best, s_in) # 只盯样本内最高的那个本质:试 2000 次,总有几个靠运气好看。这和过拟合是一回事的两面。怎么防:老实记录你试过多少个想法;提高显著性门槛;用样本外确认。
3陷阱C · 幸存者偏差(只测“还活着”的票)
模拟 1000 只股票,有些会破产归零。全体平均总收益 −32.7%,但只统计幸存者却是 +41.1%——凭空多出 73 个点!因为死掉的(−100%)被剔除了,剩下的当然好看。现实里 A 股已退市约 325 只,只在“现存股票池”回测就漏掉了它们。
怎么防:用当时点(point-in-time)的股票池,包含后来退市的票。我们的研究里“按交易日拉横截面”就是为这个。
看到诱人曲线,先问这三句
1. 参数是不是在全样本上挑的(过拟合)?
2. 你到底试了多少个想法(数据窥探)?
3. 股票池有没有漏掉退市的(幸存者偏差)?
✍ 动手做
把陷阱B的随机策略数从 2000 改成 10000,看“最高样本内夏普”会不会更唬人——试得越多,假信号越夸张。
小结
漂亮回测有三种假:参数挑出来的、试多了蒙到的、只算活人的。会怀疑,是量化最重要的能力。