03 — 发现一
文本确实加了一点。
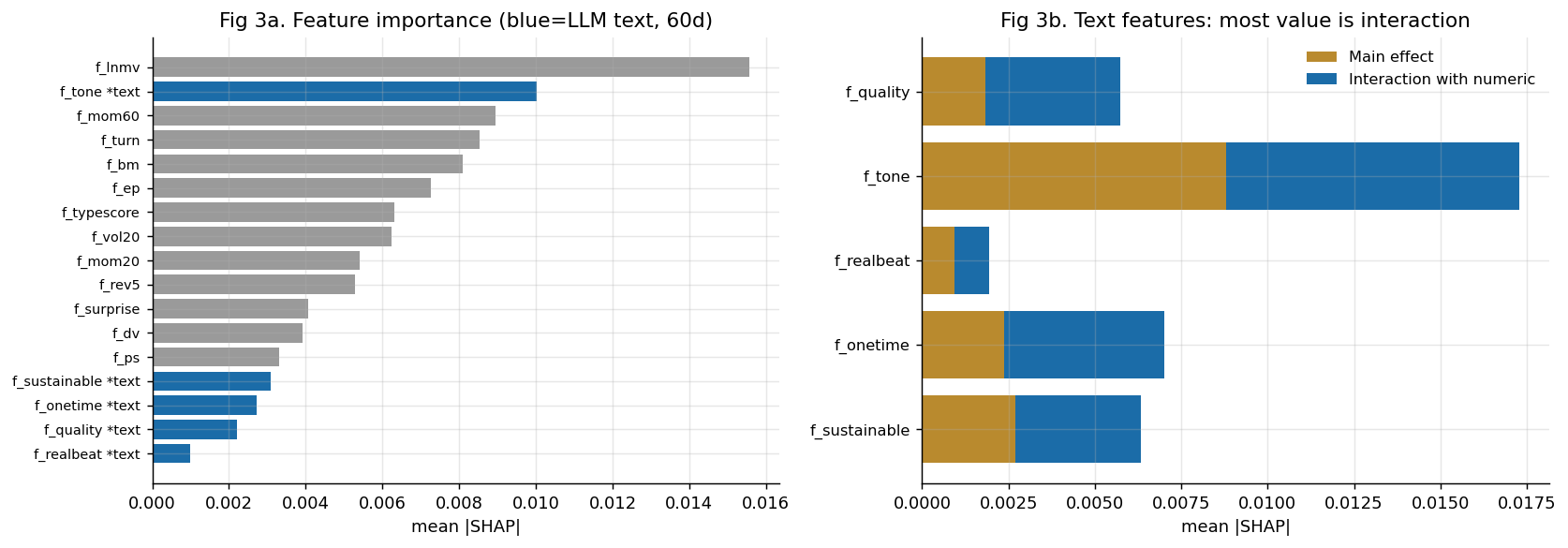
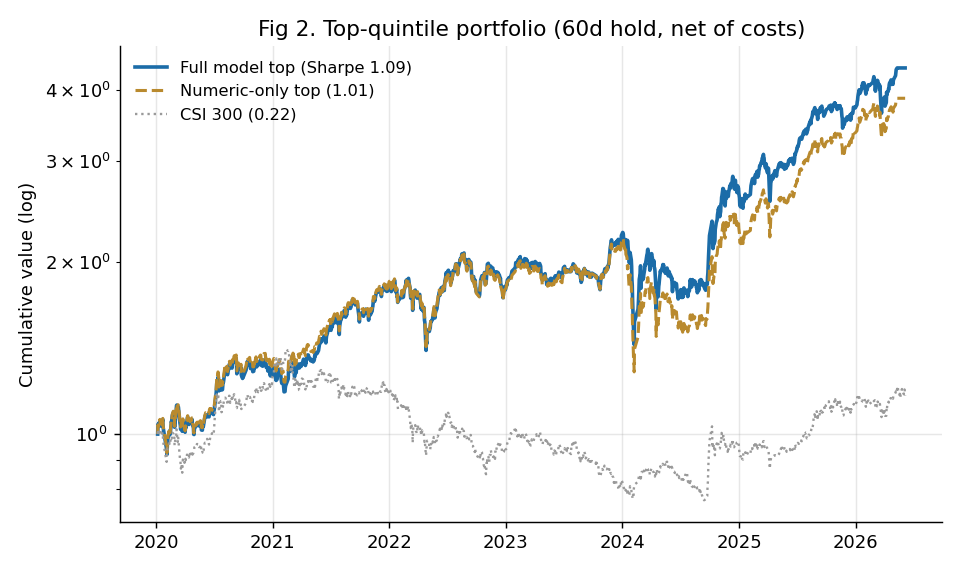
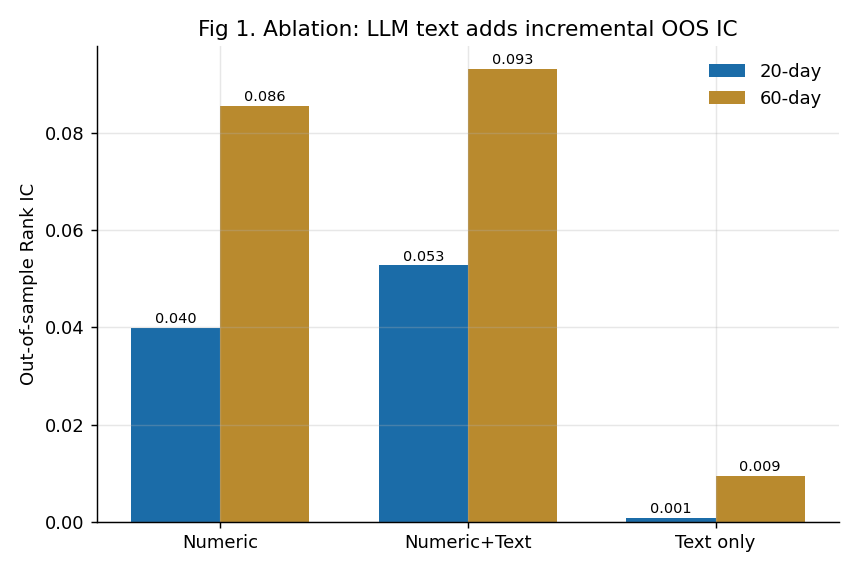
加上 AI 文本后,样本外预测力(IC)实打实地上了一个台阶:
Interactive · 拨一下开关
给模型「关掉 / 打开」AI 文本
0.040
样本外 IC(20日)
1.01
顶组组合夏普
1.60
多空夏普
这是不读文本的基线。点“数字+AI文本”看变化 →
深入一层 · 真实数字表
| 特征集 | IC(20日) | IC(60日) |
|---|---|---|
| 仅数字 | 0.0399 | 0.0856 |
| 数字+文本 | 0.0528 | 0.0932 |
| 仅文本 | 0.0007 | 0.0094 |
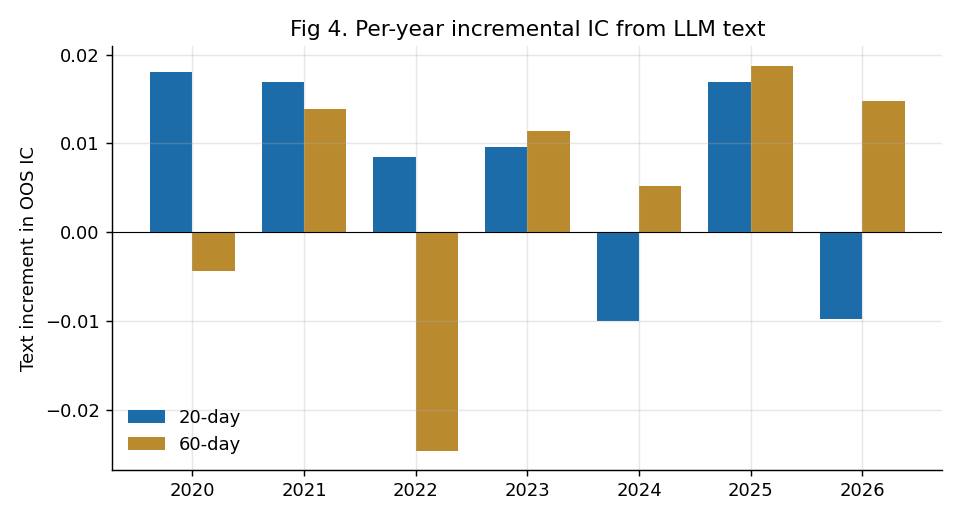
分组消融(60日):去掉估值 IC 从 0.093 跌到 0.041(估值是骨架);去掉文本 0.093→0.086(这就是文本的增量 +0.0076)。