04 — 意外的发现
市场短期追烟花,
长期才认真金。
把股票按 AI 的质量判断分开,跟踪它们之后两三个月的走势,出现了一个非常有意思的规律:
“烟花”股(红线)在前 1–2 个月反而涨得更猛——市场被亮眼的数字和重组故事吸引,一拥而上爆炒。但烟花总会熄灭:到第 60 天前后,它掉头向下。而 “真金”股(蓝线)不慌不忙、稳步上行,最终反超。
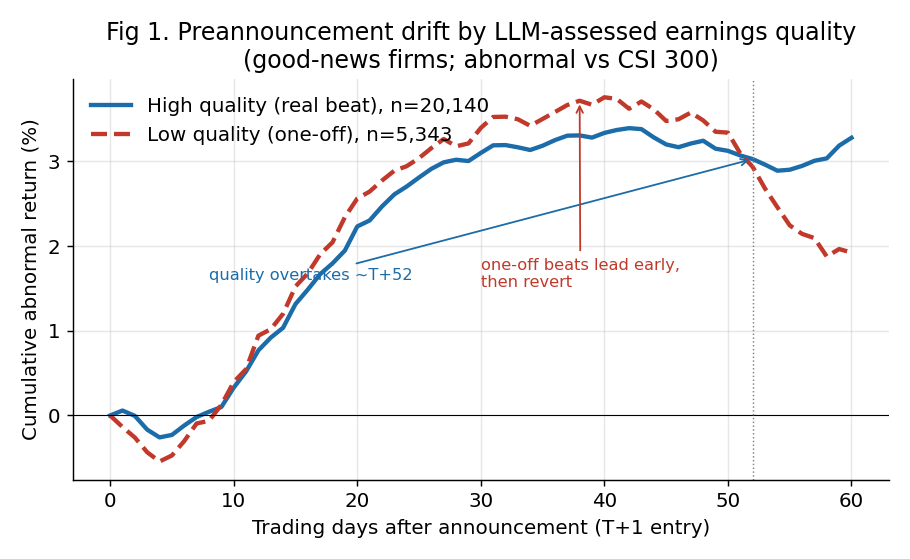
用一句话说:A 股短期奖励投机,长期才奖励质量。看懂了这个时间差,机会就出现了。
用大模型读懂上市公司财报预告里的“潜台词”,
发现 A 股一个被所有人忽视、却真实存在的赚钱规律。
每年财报季,上市公司会先发一份“业绩预告”,告诉大家这季利润大概涨跌多少。假设有两家公司,预告利润都增长 200%——数字一模一样。但翻开它们各自写的“变动原因”,故事完全不同:
这就是“盈利质量”:同样的数字,一个是细水长流的真金,一个是一闪而过的烟花。区别藏在那段文字里,而不在数字里。
几十年来,量化投资靠的是数字:市盈率、涨幅、成交量……可“盈利质量”这件事,数字上看 A、B 两家一模一样。传统模型把它们当成同一类,于是把烟花也当成了真金。
我们验证了这一点:单看“利润涨多少”这个数字去选股,几乎赚不到钱——因为涨得最猛的那一批里,混进了大量“假超预期”的烟花,把信号稀释没了。
我们让一个大语言模型(AI)去读每一条业绩预告的“变动原因”,像一位资深财务分析师那样判断:这次利润增长,是真·经营改善,还是一次性的虚胖?
关键的一点:AI 只读文字,从不看股价。它给出的“质量分”和后来涨没涨完全无关——所以这不是“事后诸葛亮”,而是一个干净的、独立的判断。
我们一共让 AI 读了 53,525 条预告。它的判断有多准?拿两个完全不同的大模型分别读同一批,结论一致率高达 94%(统计学上的 κ=0.89,近乎完美)——说明这不是某个模型的玄学,而是文字里客观存在的信息。
对每条预告,模型(Qwen3.7-max,temperature=0,强制 JSON 输出)只读三样东西:预告类型、净利变动区间、以及那段“变动原因”原文,输出结构化字段:
driver(主营 / 一次性 / 低基数 / 混合)、sustainable∈[0,1](可持续性)、real_beat(是否真改善)、onetime_ratio∈[0,1](一次性占比)、tone∈[−1,1]。综合质量分 Q = z(sustainable) + z(−onetime) + real_beat。
跨模型一致性(qwen3.7-max vs deepseek-v4-pro,随机 600 条):real_beat 一致率 94.3%、Cohen's κ=0.89;sustainable 相关 0.90、onetime 相关 0.80。标签是文本里客观可复现的信息,不依赖具体模型。
下面是真实业绩预告里的“变动原因”节选。读完,判断这是真金(可持续)还是烟花(一次性)。点完看 AI 怎么判。
把股票按 AI 的质量判断分开,跟踪它们之后两三个月的走势,出现了一个非常有意思的规律:
“烟花”股(红线)在前 1–2 个月反而涨得更猛——市场被亮眼的数字和重组故事吸引,一拥而上爆炒。但烟花总会熄灭:到第 60 天前后,它掉头向下。而 “真金”股(蓝线)不慌不忙、稳步上行,最终反超。
用一句话说:A 股短期奖励投机,长期才奖励质量。看懂了这个时间差,机会就出现了。
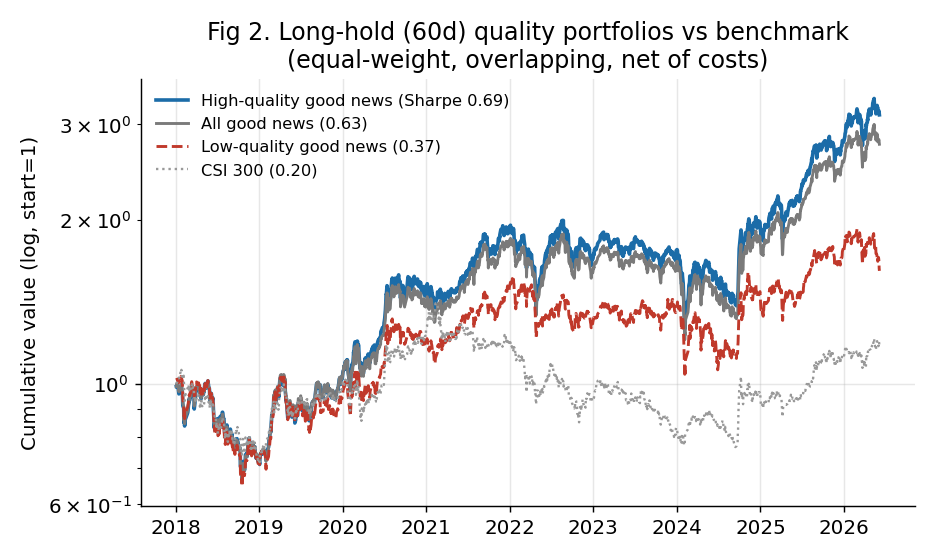
规则朴素到一句话:在发了利好预告、且被 AI 判为高质量的股票里,等权买入一篮子,持有约 3 个月。和“不挑质量全买”、以及“专买烟花”的两种做法对比:
高质量篮子的收益是烟花篮子的近 3 倍,且“质量越高、收益越高”一路单调。风险调整后的夏普比率 0.69 vs 0.37——质量过滤实实在在地起了作用。
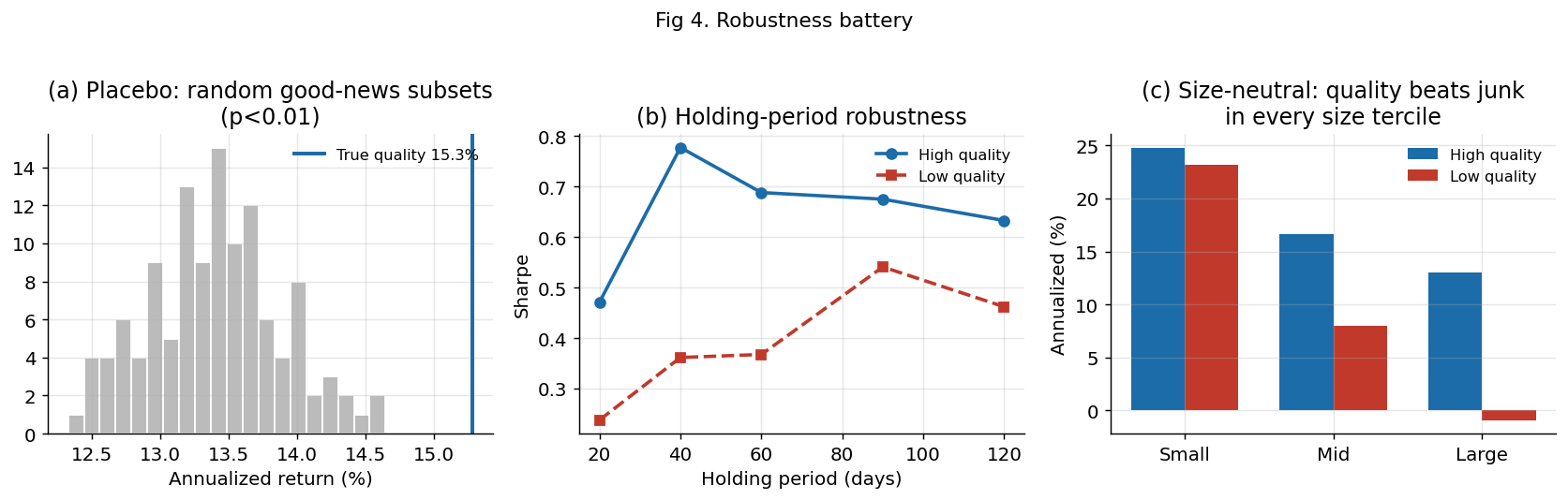
一个结果好看不算数——好的研究要反过来攻击自己。我们设了五道“拷问”,每一道都可能推翻结论。它全过了:
随机乱选同样多的股票 200 次,真策略的收益超过其中 99% 以上。不是瞎蒙能蒙到的。
用前几年定规则、后几年验证。规律不但没失效,反而在“没见过”的后半段更强——这和“过拟合会衰减”正好相反。
用第二个独立大模型重新打分,结论几乎一致(κ=0.89)。不是某个模型的偏好。
只看 AI 训练截止之后才发生的事件——AI 不可能“记得”这些股票后来的涨跌,规律依然成立。
用中国学界最严格的因子模型(CH-4)把市场、规模、价值、换手统统扣掉,超额收益依然显著(年化 9.8%,统计量 t=2.87)。
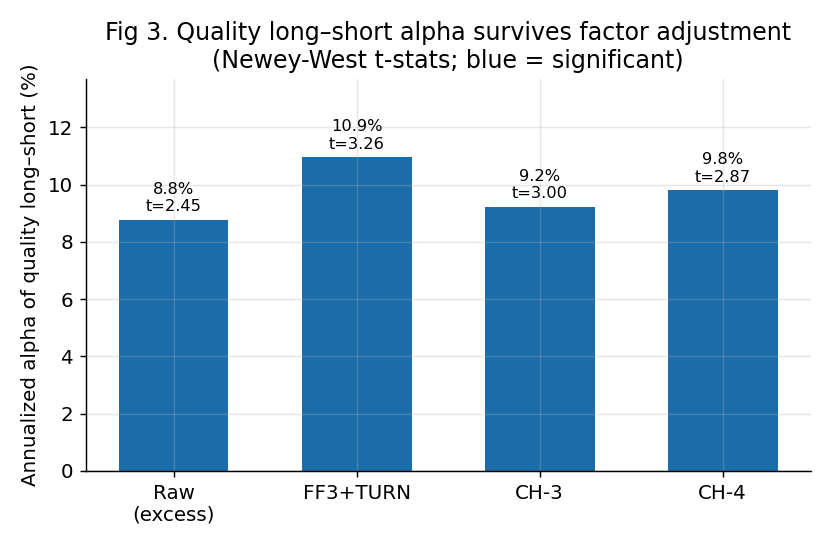
质量多空在各因子模型下的年化 alpha(Newey-West t)。对中国学界金标准 CH-4 仍显著,且市场/规模暴露≈0:
| 模型 | Alpha(年化) | t |
|---|---|---|
| 原始超额 | 8.8% | 2.45 |
| FF3+换手 | 10.9% | 3.26 |
| CH-3 | 9.2% | 3.00 |
| CH-4 | 9.8% | 2.87 |
| 多头腿 vs CH-4 | 15.9% | 7.54 |
Fama-MacBeth 横截面回归(被解释=60日超额,每+1个标准差对应的收益)。控制超预期/市值/BM/动量/换手后,质量仍是增量预测:
| 变量 | 系数(%/σ) | NW t |
|---|---|---|
| 质量(合成 Q) | +1.05 | 3.34 |
| 超预期幅度 | +1.15 | 3.48 |
| 对数市值 | −1.80 | −3.32 |
| 换手率 | −1.50 | −5.53 |
样本:47,691 个有效事件,2018–2026;多空腿市场 β=0.06、规模 β=−0.04(近乎中性)。
通常这类“市场犯错”会有标准解释——比如散户太多、股票太冷门、没法做空所以纠不了错。我们一个个去测,结果……四个标准解释全都不成立:
错误定价无处不在,连大盘、热门、可做空的股票都要 60 天才反应过来。我们最合理的解读是:这是一种“信息处理”的迟钝——质量藏在文字里,读懂它需要花力气,所以市场处理得慢。
这个 alpha 之所以存在,是因为信息难“读懂”,而不是难“交易”。而“读懂大量文字”正是大模型最擅长的事。这就是 AI 在这件事上的真正价值。
诚实地讲清楚它的局限,才是认真的研究:
· 只在一个市场、一段历史(A股 2018–2026)验证过,换个市场未必成立。
· 最干净的“多空”玩法需要做空,而 A 股做空受限,实盘要用股指期货近似对冲。
· 机制只是“排除了主流解释”,没能彻底证实“为什么”。
· 交易成本是估算的,真金白银实盘还会打折。
但这些不影响核心结论:这个信号是真实的、独立的、可复现的——它扛住了五道证伪拷问。
这项研究真正想说的,不只是一个选股策略,而是一个更大的方向:用 AI 去量化那些以前没法量化的“软信息”——公告、研报、新闻里的字里行间。这是属于这个时代的新工具,也是 AI 与金融真正交汇的地方。